Benchmarks
EasyLambda aims to provide a high level parallel programming abstraction while incurring minimal overheads. It scales from multiple cores to hundreds of distributed nodes without any need to deal with parallelism in user code.
It uses modern C++ features to be expressive and succinct. It builds parallelism over high performance MPI library. [1].
The section demonstrates performance and ease of programming with easyLambda with the help of experiments carried out on an HPC cluster, cloud cluster and multi core machine.
Performance
The benchmarking results of easyLambda programs for the following problems are presented.
wordcount: The wordcount problem involves counting the number of times each word has occurred in text data. The code for the problem begins with file read operation followed by a reduce with partitioning that may entail inter-process communications. The example code for wordcount problem is easy to find for a MapReduce like library that has reduce with partitioning. [code] [walkthrough]
logreg: Logistic regression is a popular classification algorithm in machine learning. The logistic regression training is done using iterative stochastic gradient descent which is also used in many other machine learning tasks such as neural networks. It involves reading the data once, followed by multiple iterations on the data to improve the weights of the classifier. The iterations involve calculation of the gradient which is a linear operation on the number of dimensions of the input. Each iteration may entail inter-process communications. Classic MapReduce frameworks such as Hadoop involve disk operations for each iteration making the iterative algorithms relatively slow when compared to modern frameworks like Spark. [code] [walkthrough]
pi: Monte Carlo method is a randomized method which can be used to estimate value of pi. The solution code does not access filesystem. It involves a reduce without partitioning that entails communication to a single process. It can be implemented with bare MPI using
MPI_reduceoperation. [code] [walkthrough]heat: The solution for the problem provides explicit finite difference solution for one dimensional heat equation. It requires filesystem writes in order to write the results of the cells/grid. It involves multiple iterations. In each iteration, a process communicates solution at the edge cells with its adjacent processes. [code]
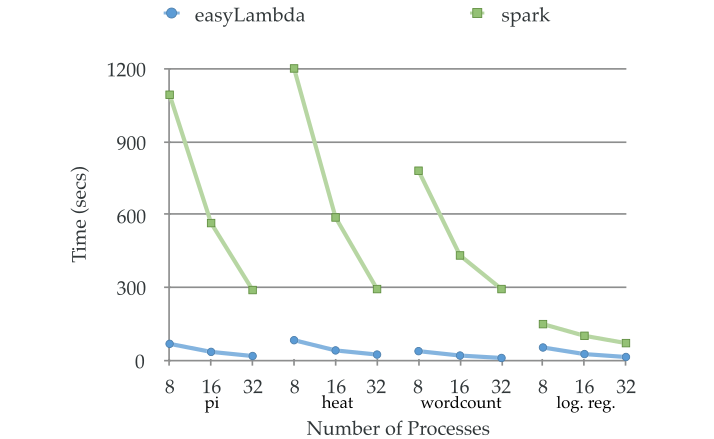
The following figure shows execution times of easyLambda and Spark codes for the problems on different number of processes. The codes were executed on amazon’s elastic cloud cluster (EC2) with m3.2xlarge instance type. To use easyLambda on EC2, StarCluster with NFSv3 filesystem was used. Spark uses HDFS as filesystem that is deployed by standard spark-ec2 scripts.
The codes are taken from the examples of the libraries except for the problem ‘heat’ in Spark. For this problem, the Spark code used is isomorphic to the easyLambda example code for the same.
In the benchmarks, easyLambda invariably performs around an order of magnitude better. However, Spark provides fault tolerance and better data handling features that easyLambda lacks as of now. There are also differences in the basic philosophy, target community and use cases of the two.
The following table shows benchmark results for the problems executed on a Linux cluster with NFSv3 filesystem over TCP. The problems scale nearly linear when the problem size is sufficient compared to number of processes. Since, similar code for pi problem can be written using bare MPI in a straight forward way using MPI_Reduce, it is compared with pi implementation of easyLambda. The bare MPI code (pi-MPI) and easyLambda code (pi-ezl) have similar performance.
| processes | 12 | 24 | 48 | 96 | data |
|---|---|---|---|---|---|
| pi-ezl | 48s | 55s | 58s | 58s | weak |
| pi-MPI | 46s | 54s | 58s | 59s | weak |
| trials(1e11) | 0.125 | 0.25 | 0.5 | 1 | weak |
| wordcount | 178s | 114s | 82s | 80s | 12.5GB |
| logreg | 190s | 91s | 50s | 36s | 2.9GB |
| heat | 300s | 156s | 81s | 42s | 1e8 pts |
Time of execution is in seconds for different problems. Weak scaling is used for pi with number of trials given below the execution times.
The following table shows benchmarks for logreg problem with more number of processes and bigger data sizes on a Linux cluster with Lustre filesystem over RDMA. Over RDMA the wordcount with similar data takes less than 20 seconds for lowest number of processes viz. 24 and reduces to around 10 seconds for 384 processes. The pi problem does not benefit from the filesystem and show similar performance as in NFSv3 cluster.
| processes | 24 | 48 | 96 | 192 | 384 | data |
|---|---|---|---|---|---|---|
| logreg | 336s | 187s | 100s | 55s | 30s | 48GB |
| logreg | 23s | 24s | 26s | 27s | 30s | weak |
| data(GB) | 3 | 6 | 12 | 24 | 48 | - |
EasyLambda scales well on multi-cores as shown in the following table. The performance is compared with MR-MPI library. The code for the wordcount problem in MR-MPI library is taken from its examples.
| processes | 1 | 2 | 4 | data |
|---|---|---|---|---|
| wordcount-ezl | 27s | 15.5s | 12.4s | 1200MB |
| wordcount-MRMPI | 27s | 34s | 37s | 1200MB |
| logreg. | 120s | 63s | 38s | 450MB |
| pi-MC | 111s | 56s | 39s | 4x10^9trials |
Other problems like post processing atomic simulations, machine learning on images with high dimensional features show similar scaling trends. However, with higher dimensional matrices in machine learning the cache effects make the benchmarks little fluctuating, but the overall scaling remains same. The current logistic regression uses vectorized simd operations for multiplications when compiled with optimization flag. The openMP thread model does not give as good performance as auto vectorization. Other libraries can be used along with easyLambda library for heterogeneous parallelism.
Ease of Programming
The approximate lines of user code for the implementation of the problems in different parallel languages and libraries is shown in the following figure. The codes whenever available, are taken from the example codes of the libraries. The language and platform specific lines that are not related to the problem are not counted.
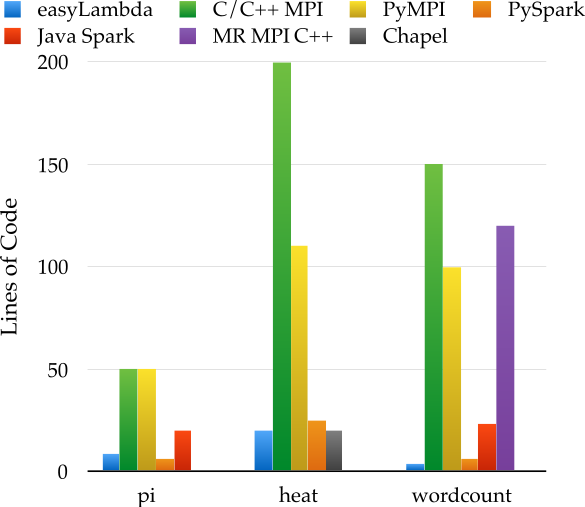
Arguably, the number of lines of code is a decent indicator of readability, less error prone code and productivity [2] [3].
Versatility
The easyLambda library has been used for training & testing image classifiers in parallel. It has been used with libraries like openCV, Dlib, tiny-dnn etc. Besides data analytics and machine learning it has also been used to create post-processors for scientific computation with multiple reusable dataflows. EasyLambda models dataflow as a black box componenet that can be characterized solely by its input and output types. The dataflows can be returned from a function, passed around, attached to another dataflow etc.
Acknowledgements
I wish to thank eicossa and Nitesh for their continuous help in pulling this through.
Leave a Comment