Welcome
Welcome to easyLambda and thanks for your interest. The site aims to be a comprehensive guide for easyLambda.
What is easyLambda
EasyLambda is header only C++14 library for data processing in parallel with functional list operations (map, filter, reduce, scan, zip) that are tied together in type–safe dataflow.
EasyLambda is parallel, it scales from multiple cores to hundreds of distributed nodes without any need to deal with parallelism in user code.
EasyLambda is fast. It has minimal overhead in serial execution and builds upon high performance MPI parallelism that is known to be more efficient than any other comparable work [1].
EasyLambda is as expressive and succinct as writing a declarative query with SQL or working with spreadsheets, thanks to the column selection for composition of functions and many generic algorithms such as super configurable parallel file reader, predicates, correlation, summary etc.
EasyLambda is intuitive and easy to understand with its uniform property based (or ExpressionBuilder) interface for everything from configuring parallelism to changing behavior of generic algorithms to routing dataflow.
EasyLambda is easily interoperable with other libraries like standard library or raw MPI code, since it uses standard data types and enforces no special structure, data-types or requirements on the user functions.
Why easyLambda
EasyLambda is a good fit for the following tasks:
- table/list processing and analysis from CSV or flat text files.
- post-processing of scientific simulation results.
- running iterative machine learning algorithms.
- parallel type-safe data reading.
- to play with dataflow programming and functional list operations.
Since, it can smoothly interoperate with other libraries, it is possible to add distributed parallelism using easyLambda to the existing libraries or codebase when its programming abstraction fits well e.g. it can be used along with bare MPI code or with a machine learning library to add distributed training and testing.
EasyLambda will also interest you if you
- are a modern C++ enthusiast
- want to dabble with metaprogramming
- like functional and dataflow programming
- have cluster resources that you want to put to use in everyday tasks without much effort.
- have always wanted a high-level MPI interface.
Benchmarks
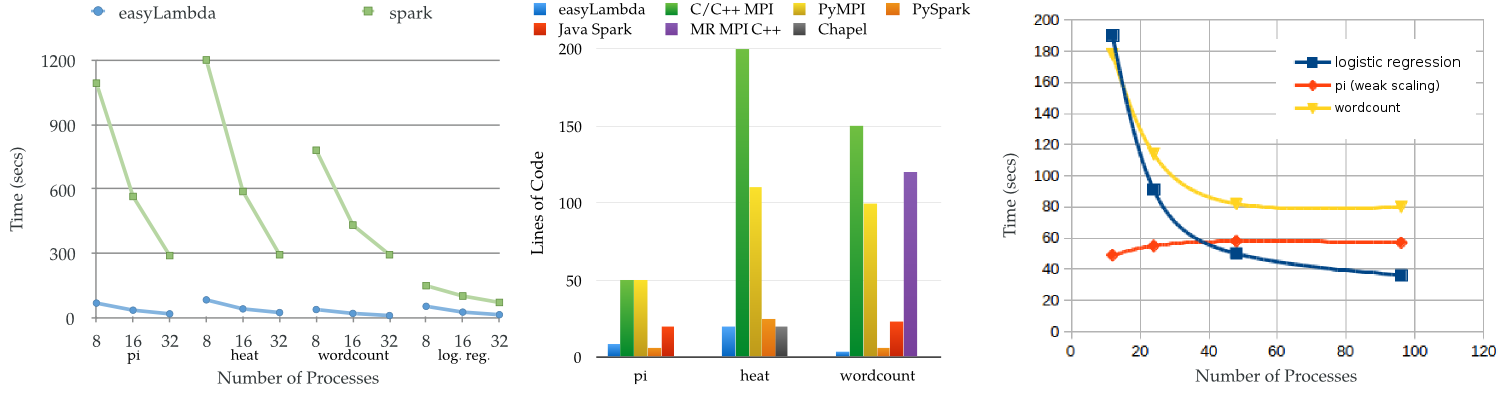
EasyLambda combines the efficiency of MPI with a high level programming abstraction. With easyLambda you get easy to understand code with good run-time performance. Check out the benchmarks and comparisons for performance and ease of use.
Getting Started
Check out the Getting Started section to know how to install and use . The library can also be used on aws elastic cloud or single instance.
You can check detailed walkthrough of example codes here, starting from simple examples and moving to real world problems ranging from scientific simulations to supervised machine learning from everyday data analytics tasks.
If you are new to functional or modern C++, syntax may look unfamiliar at first but there is a very minimal set of things to understand before you begin writing code with easyLambda. This guide tries to put these details together. In the process you will be introduced to some concepts in modern C++, functional programming and dataflow programming that are helpful beyond this library as well.
Contributing
Suggestions and feedback are welcome. Feel free to contact via mail or issues for any query.
Some of the possible directions of improvement:
- compile time optimization
- use of specialized data structures in various units like reduce etc.
- addition of more examples e.g. neural nets, simulations etc.
- design simplifications
- parallelism optimization
- code reviews
- documentation
Possible ideas for future extenstions:
- fault tolerance
- algorithms / functions to plot streaming and buffered data
- domain specific algorithms
- MPI single-sided communications
- Experiments to extend current programming abstraction to cover more problems like domain-decomposition etc.
Check the blog and internals for discussion on some exciting internal and implementation details.
Examples
Programming with pure functional dataflows is similar to the way we think in spreadsheet programs, SQL queries or declarative commands like awk, cut etc, without any restrictions (you can apply any C/C++ function to data columns).
Let’s say we have data with ten columns, we want to add first two columns and find how many of them add up to more than a hundred. In spreadsheets one way of doing this can be as follows:
- write formula A1 + B1 in the first row of a new column.
- apply the same formula to all rows of the new column by auto-filling.
- filter the rows for greater than 100 value of last / 11th column.
- count the filtered rows.
Here, is the easyLambda code for the same.
ezl::flow(dataSource)
.map<1, 2>(std::plus)
.filter<11>(ezl::gt(100))
.reduce(ezl::count(), 0).dump()
.run();The data flows to the functions wrapped inside units (map, filter, reduce) one after another. The map step applies a C / C++ function to all rows and adds the resulting column(s) at the end of the row. The number in the angular brackets specify column number(s) to work on. The dataSource can be from a list variable, file or anything like network etc. because source can also be just another C / C++ function.
Example wordcount
The following program calculates frequency of each word in the data files.
auto reader = fromFile<string>(argv[1]).rowSeparator(' ');
ezl::rise(reader)
.reduce<1>(ezl::count(), 0).dump()
.run();The dataflow starts with rise and subsequent operations are added to the dataflow. In the above example, the dataflow starts with reading data from file(s). fromFile is a library function that takes column types and file(s) glob pattern as input and reads the file(s) in parallel. It has a lot of properties for controlling data-format, parallelism, denormalization etc (shown in demoFromFile).
In reduce we pass the index of the key column to group by as template parameter (inside < >), a library function for counting and initial value of the count.
Example pi (Monte-Carlo)
Following is the dataflow for calculating pi using Monte-Carlo method.
ezl::rise(ezl::kick(1000)) // 1000 trials shared over all processes
.map([] {
return pow(rnd(), 2) + pow(rnd(), 2);
})
.filter(ezl::lt(1.))
.reduce(ezl::count(), 0)
.map([](int inCircleCount) {
return (4.0 * inCircleCount / 1000);
}).dump()
.run();The dataflow starts with rise in which we pass a library function to call the next unit a number of times. The steps in the algorithm have been expressed with the composition of small operations, some are common library functions like count(), lt() (less-than) and some are user-defined functions specific to the problem.
Example cods2016
Here is another example from cods2016. The input data contains student profiles with scores, gender, job-salary, city etc.
auto scores = ezl::fromFile<char, array<float, 3>>(fileName)
.cols({"Gender", "English", "Logical", "Domain"})
.colSeparator("\t");
ezl::rise(scores)
.filter<2>(ezl::gtAr<3>(0.F)) // filter valid domain scores > 0
.map<1>([] (char gender) { // transforming with 0/1 for isMale
return float(gender == 'm');
}).colsTransform()
.reduceAll(ezl::corr<1>())
.dump("", "Corr. of gender with scores\n(gender|E|L|D)")
.run();The above example prints the correlation of English, logical and domain scores with respect to gender. We can find similarity of the above code with steps in a spreadsheet analysis or with SQL query. We select the columns to work with viz. gender and three scores. We filter the rows based on a column and predicate. Next, we transform a selected column in-place and then find an aggregate property (correlation) for all the rows.